- Published on
Data Engineering Zoomcamp | Week 2.5 ETL, API to GCP using Parquet with Partitioning through PyArrow. Pipeline in Mage |
Very excited to be using PyArrow today to paritition a dataframe and load this to Google Cloud Storage which will act as the file system 😎.
Of course, we'll be building the pipeline in Mage.
In a previous blog, we built an ETL pipeline and we used pandas. So why switch it up to PyArrow?! Both have their respective benefits. The most important thing to note is that pandas is row-oriented and pyarrow is column-oriented. Choosing between which type of structure to use ultimately depends on the use case and the type of queries you'd like to run. In my opinion, the ability to be able to use different libraries will only add another notch to the belt, plus the skillset of a modern data engineer is very much like a swiss army knife!
ChatGPT provides a really nice comparison:
Pandas vs PyArrow: High-Level Summary
Pandas:
- Use Case: Ideal for data manipulation and analysis in memory, especially for smaller to medium-sized datasets (fits comfortably in RAM).
- Strengths:
- Easy-to-use data structures (DataFrame, Series) for intuitive data handling.
- Rich functionality for data cleaning, transformation, and analysis (e.g., groupby, merge).
- Excellent integration with other Python libraries for data science (e.g., Matplotlib, Scikit-learn).
- Considerations:
- Performance may degrade with very large datasets (those exceeding available RAM).
- Not optimized for distributed computing or efficient storage formats.
PyArrow:
- Use Case: Designed for high-performance analytics and large-scale data processing, particularly with big data and distributed systems.
- Strengths:
- Columnar storage format (Parquet) for efficient I/O operations and compression.
- Optimized for processing large datasets that exceed available memory, leveraging disk and distributed computing.
- Integration with Apache Arrow for efficient data interchange between systems and languages (e.g., Python, R, Java).
- Considerations:
- Requires familiarity with data serialization and columnar storage concepts.
- More suited for advanced analytics pipelines and distributed computing frameworks (e.g., Spark, Dask).
When to Choose One Over the Other:
Pandas: Choose Pandas when you:
- Work with datasets that fit comfortably in memory.
- Need quick and interactive data exploration and analysis.
- Prefer simplicity and ease of use over performance optimizations.
- Are working in a single-machine environment and not dealing with big data scale.
PyArrow: Choose PyArrow when you:
- Deal with very large datasets that exceed available memory (terabytes to petabytes).
- Require efficient I/O operations and storage formats (e.g., Parquet) for data processing and analytics.
- Need to integrate with distributed computing frameworks or parallel processing systems.
- Seek high-performance analytics and optimized data serialization for large-scale data pipelines.
ETL pipeline
Extract
One of the wonderful things in Mage is that everything is stored as code. This means that blocks we've previous created are up for grabs! This is also VERY nice if you want to update a block and flood it through to multiple pipelines! 😌🚀.
standard batch pipeline: 
Then expand the Data Loaders section. Locate the block you built previous for loading data from the url using pandas. Simply click on it and drag and drop! 😱.

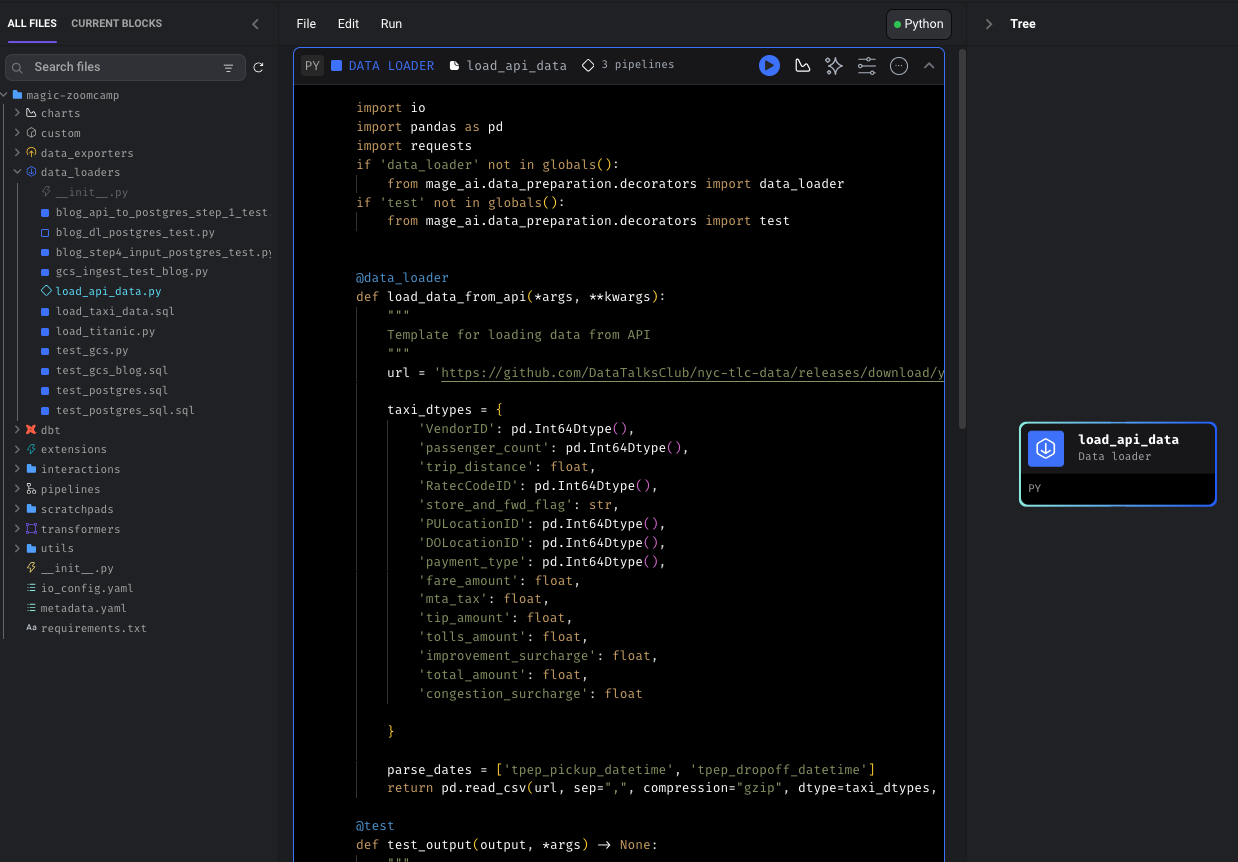
and voila! Extract component has been done.
Transform
For our transformation section, we won't use the previous transformation block we created using pandas (although we could!). I'd like to use PyArrow to filter out passenger journeys that somehow didn't contain passengers 😆.

Code here:
import pyarrow as pa
import pyarrow.parquet as pq
import pyarrow.compute as pc
if 'transformer' not in globals():
from mage_ai.data_preparation.decorators import transformer
if 'test' not in globals():
from mage_ai.data_preparation.decorators import test
@transformer
def transform(data, *args, **kwargs):
#Partition column:
data['tpep_pickup_date'] = data.tpep_pickup_datetime.dt.date
pa_tbl = pa.Table.from_pandas(data)
print("Rows before filtering with pyarrow", pa_tbl.num_rows)
pa_tbl = pa_tbl.filter(pc.field('passenger_count')!=0)
print("Rows after filtering with pyarrow", pa_tbl.num_rows)
return data
@test
def test_output(output, *args) -> None:
"""
Template code for testing the output of the block.
"""
assert output is not None, 'The output is undefined'
Load
Here we'll take our PyArrow table and load it into GCS using a partition.
The documentation for PyArrow is great, specifically, take note of the Reading and Writing the Apache Parquet Format section: https://arrow.apache.org/docs/python/parquet.html
They provide this example:
# Remote file-system example
from pyarrow.fs import HadoopFileSystem
fs = HadoopFileSystem(host, port, user=user, kerb_ticket=ticket_cache_path)
pq.write_to_dataset(table, root_path='dataset_name',
partition_cols=['one', 'two'], filesystem=fs)
All we'd have to change the is File System to be a GCS file system.
Now, the documentation for the GCSFilesystem: https://arrow.apache.org/docs/python/generated/pyarrow.fs.GcsFileSystem.html
The function needed:
pyarrow.fs.GcsFileSystem
class pyarrow.fs.GcsFileSystem(bool anonymous=False,
*, access_token=None, target_service_account=None,
credential_token_expiration=None, default_bucket_location=u'US',
scheme=None, endpoint_override=None,
default_metadata=None,
retry_time_limit=None,
project_id=None)
Whilst all of these parameters can be given, only one thing is definitely required:
By default uses the process described in https://google.aip.dev/auth/4110 to resolve credentials.
If not running on Google Cloud Platform (GCP), this generally requires the environment variable GOOGLE_APPLICATION_CREDENTIALS
to point to a JSON file containing credentials.
This indicates all we'll need to create a environment variable with that particular alias GOOGLE_APPLICATION_CREDENTIALS. We'll leverage the OS library for this. Interestingly, the credentials that are created also point contain the project they were created within so the GCSFileSystem will take them by default (if supplied none).
All that's left it to create a Data_Exporter block:
import os
import pyarrow
if 'data_exporter' not in globals():
from mage_ai.data_preparation.decorators import data_exporter
@data_exporter
def export_data(data, *args, **kwargs):
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = '/home/src/homework1-dezoomcamp-cc221b996f06.json'
filesys = pyarrow.fs.GcsFileSystem()
root_path='de-zoomcamp-mage-bs/ny_taxi'
#Converting DF back to PyArrow Table
data = pyarrow.Table.from_pandas(data)
pyarrow.parquet.write_to_dataset(data, root_path, partition_cols=['tpep_pickup_date'], \
filesystem=filesys)
We only need to define the root_path and the partition_cols. Root path is where the files will land, so we give the bucket and a parent folder. Annoyingly, and this is likely a problem between person and chair, Mage has passed a Pandas DataFrame between the transform block and the data_exporter block. Therefore, I had to convert it back to a PyArrow table.

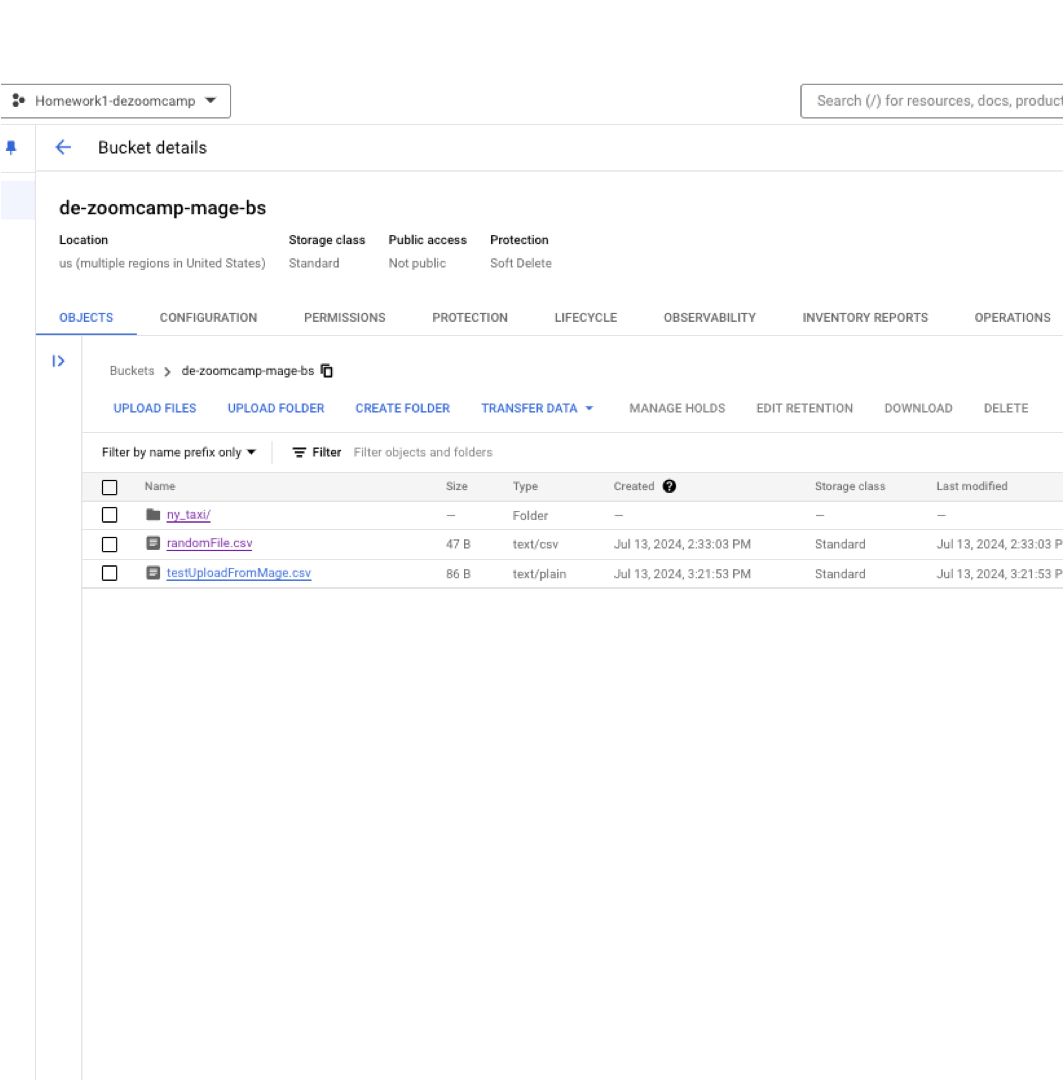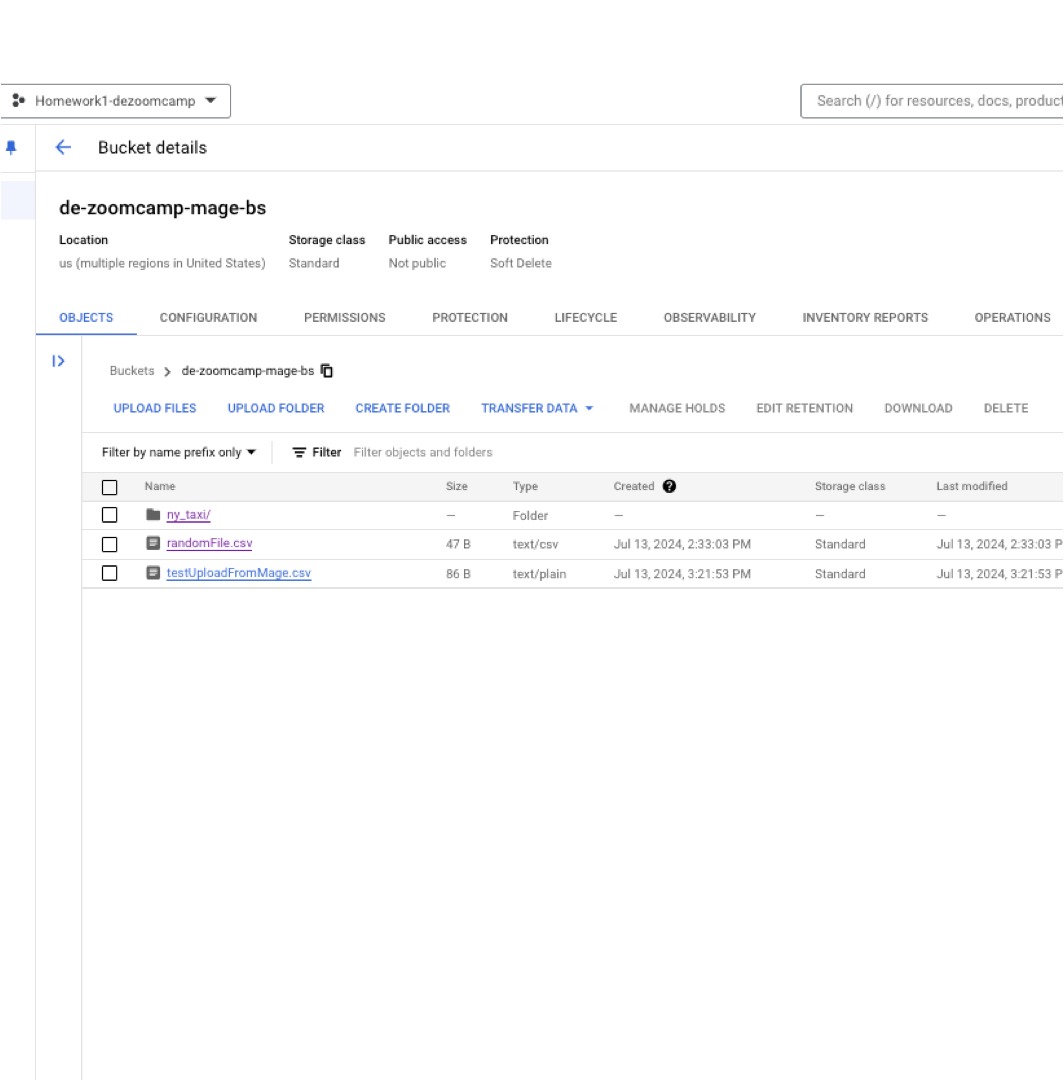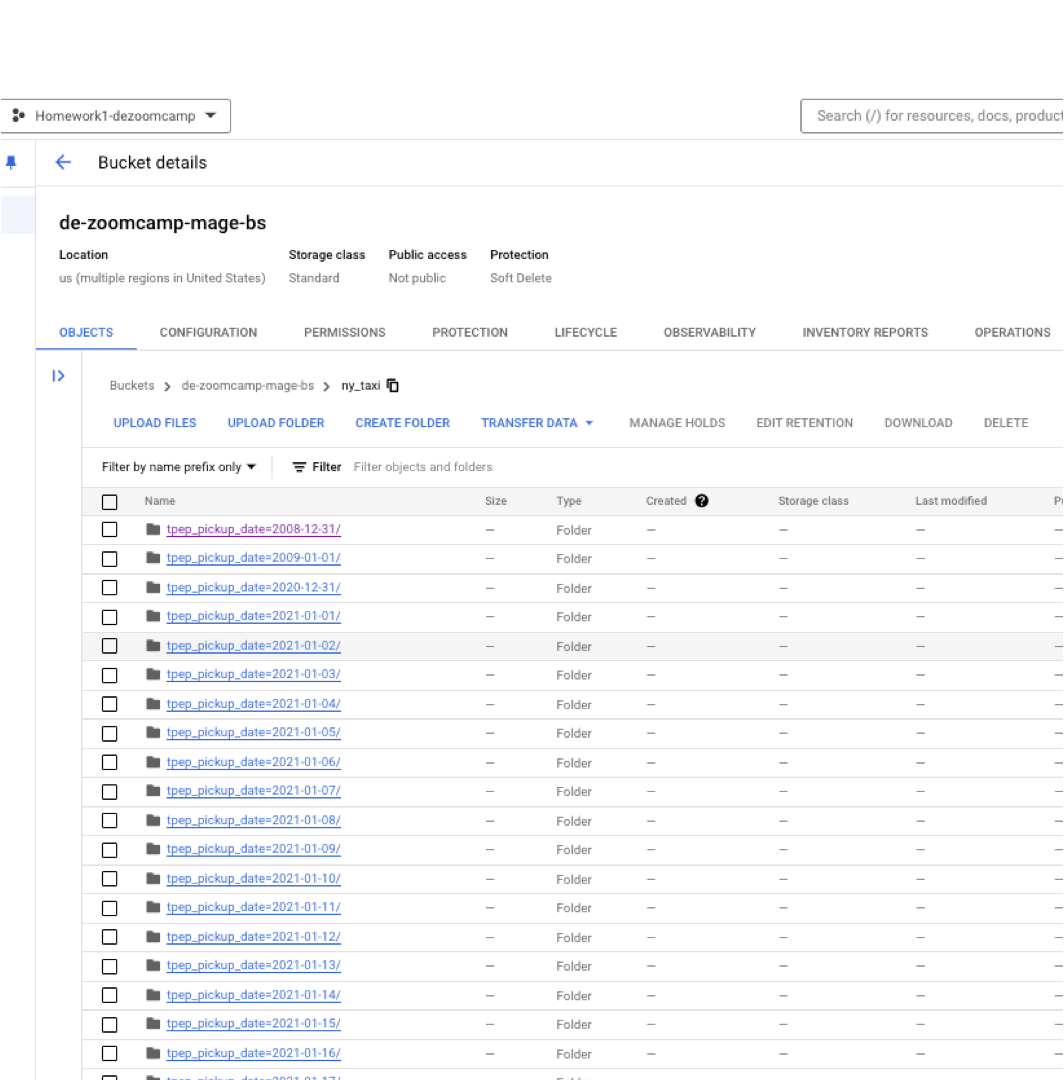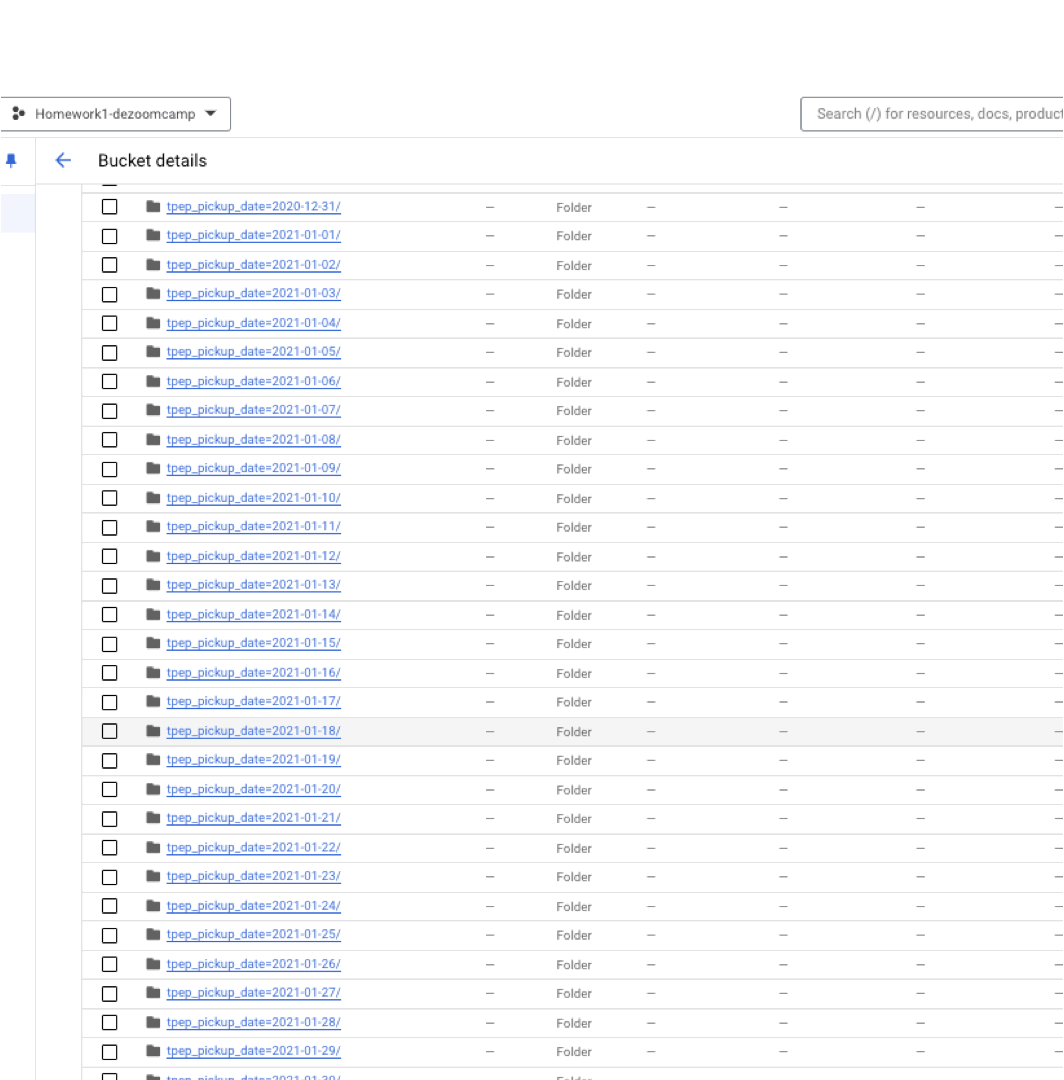
And there we have it! 🚀. Had a blast with this one 😎. Catch you in the next.